🤖 Latest AI models yet to master new benchmarks. Aus lagged research funds. US led health spending per capita.
Chart of the Day #526 looks at Australia’s state funding for research, global healthcare spending per capita, and latest AI benchmarks.
Welcome,
MSDE to boost vocational education and skills. Arizona strengthens semi-conductor Workforce. Kenya And UK deepen healthcare workforce partnerships. MSU to offer AI studies amid push for digital-ready workforce.
Sparkli releases an AI-based interactive learning app designed for early childhood education. BSCTC and Kentucky Power partner for workforce training. IIT Madras has launched six free Hindi-language AI courses on its SWAYAM Plus platform.
In today's newsletter:
💵 Funding. Australia’s state funding for research lagged behind peer nations
⚕️ Health Skills. US topped healthcare spending per capita
🤖 Artificial Intelligence. Latest AI models still discovering tougher benchmarks
Thanks for reading!
Not a subscriber yet?
💵 Australia’s state funding for research lagged behind peer nations
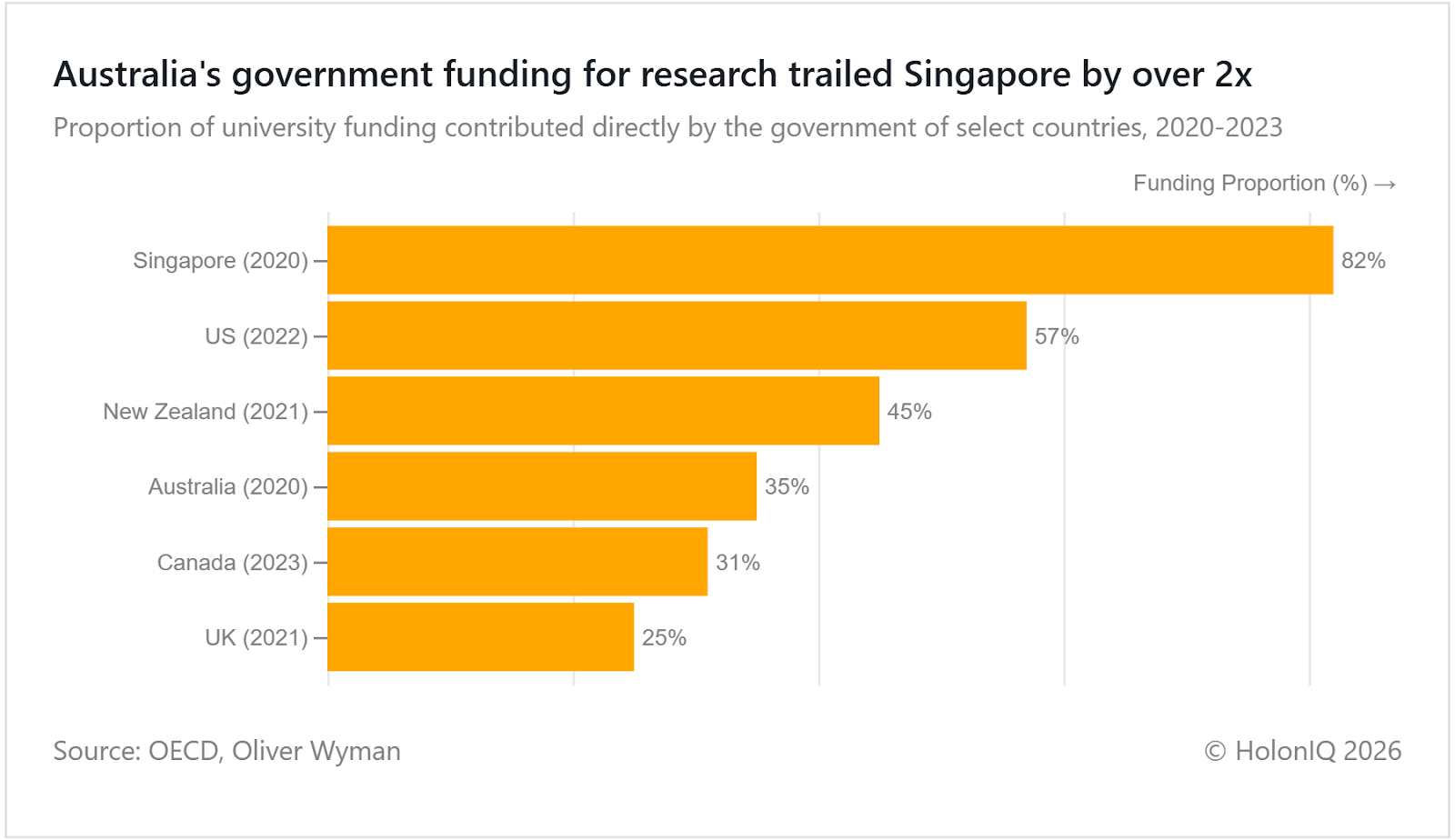
Australia’s higher education sector has been strained by low government research funding, trailing peers like Singapore and the US, after years of dependence on international student fees. Recent caps on international enrolments exposed funding fragility, forcing restructuring across universities and eventually raising the imposed enrolment cap. The Australian government is boosting state-led research funding, mission-based grants, and industry-linked R&D to rebalance university finances and reduce overdependence on overseas tuition fee income.
⚕️ US topped healthcare spending per capita
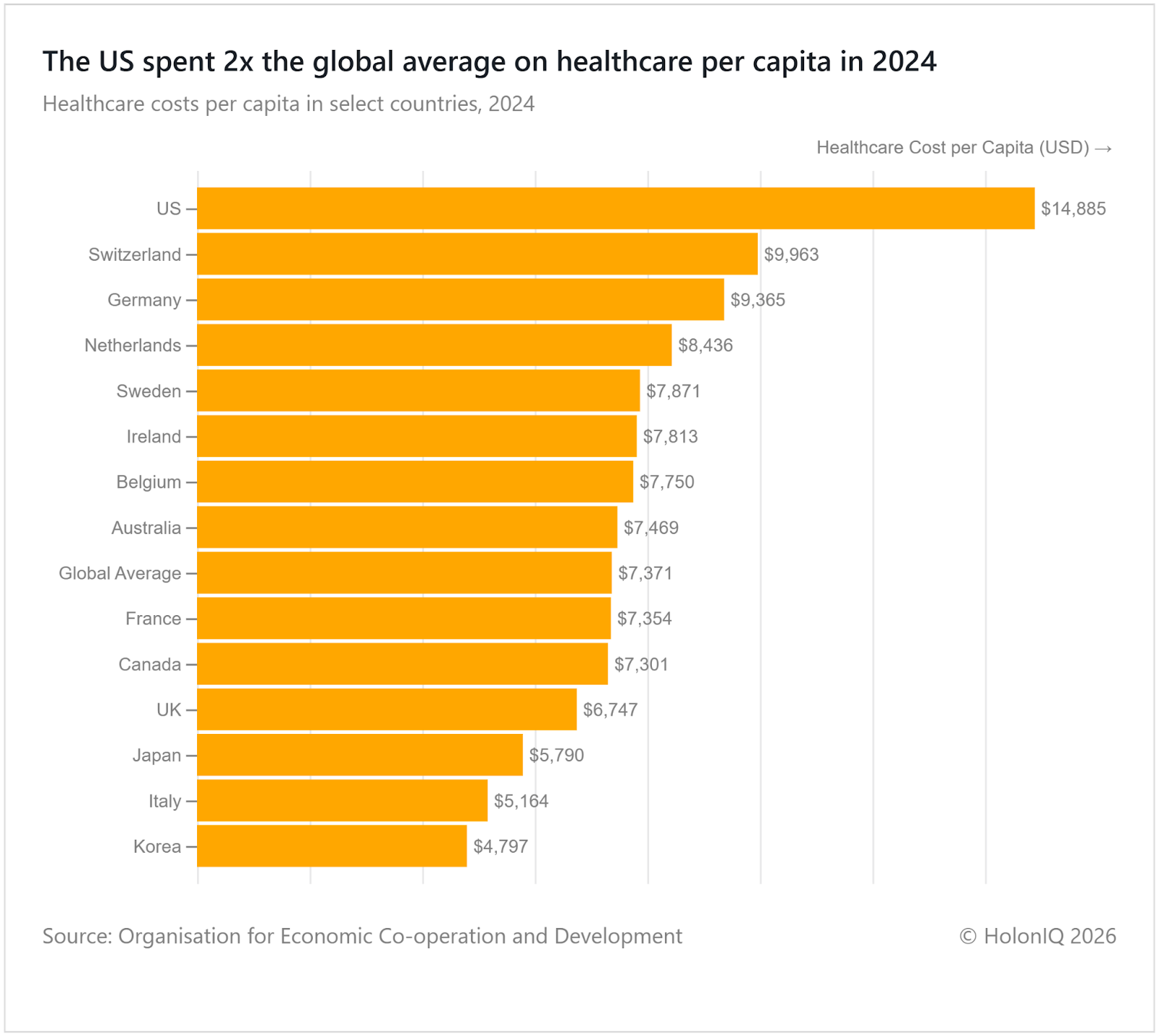
In 2024, the US spent nearly $15K per capita on healthcare, far above peers, driven largely by higher prices for hospitals, procedures, and administration, rather than greater service use. Despite this spending, access gaps persist, with affordability and uneven coverage. The Big Beautiful Bill intensifies scrutiny on cost controls and subsidies, and reshaping funding flows towards programmes such as Medicaid. However, price-setting and provider market power are unresolved drivers of high costs.
🤖 Latest AI models still discovering tougher benchmarks
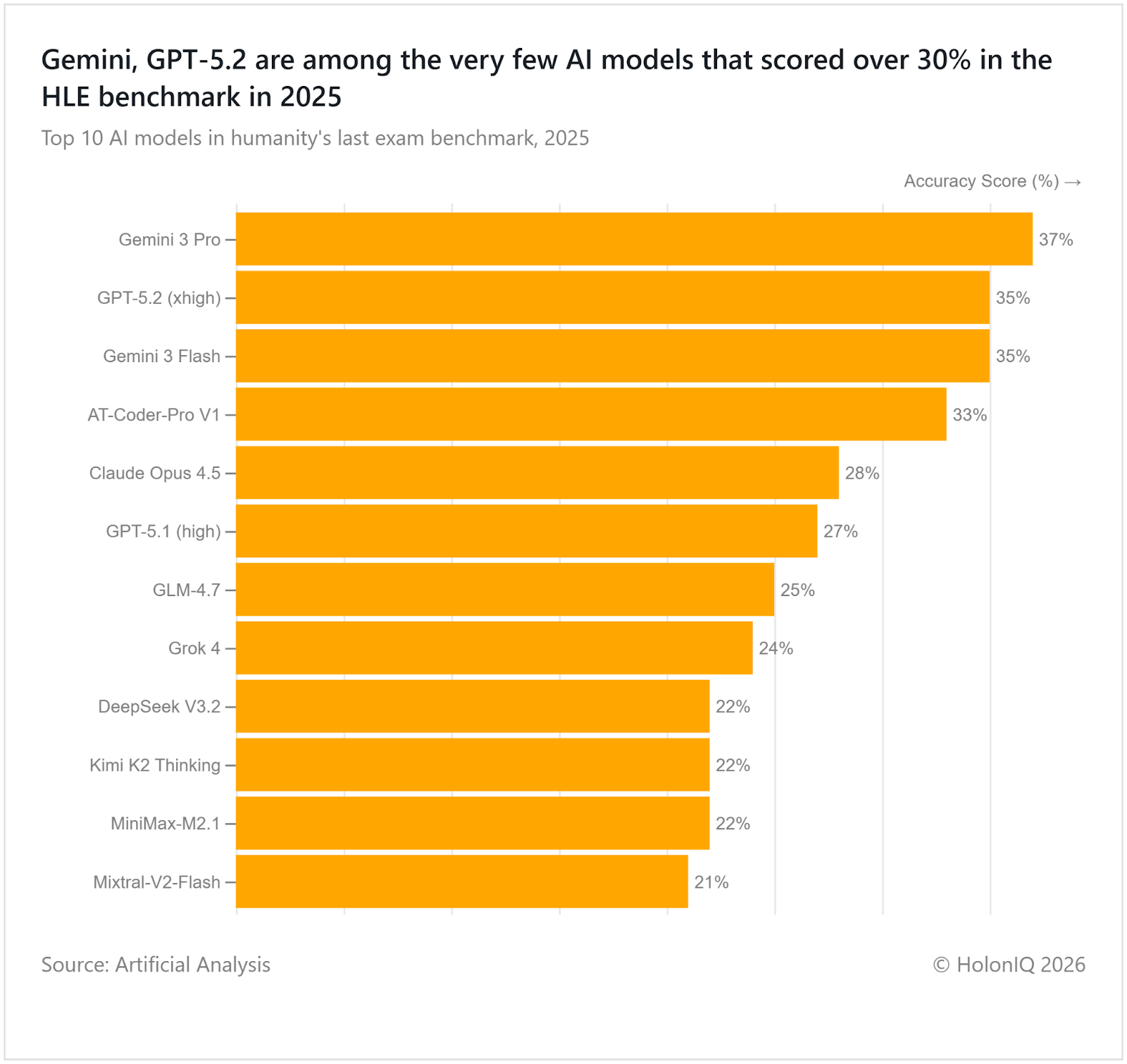
Humanity’s Last Exam (HLE) is a frontier benchmark designed to test expert-level reasoning, combining multi-step logic, cross-domain knowledge, math, coding, and adversarial questions resistant to memorisation. Top scores remain low, with Gemini 3 Pro at 37% and GPT-5.2 at 35%, signalling genuine difficulty compared to regular benchmarks. As models saturate legacy benchmarks, HLE shows LLMs now excel at pattern tasks but still struggle with deep reasoning, uncertainty, and synthesis, highlighting the gap between competence and true intelligence.
Like getting this newsletter? Request a demo for unlimited access to over one million charts
Thank you for reading. Have a great week ahead!
Have some feedback or want to sponsor this newsletter? Let us know at qs.com.